
AssembleCrash
Work with register
1

这里还是建议先看视频Assembly Crash Course20220830
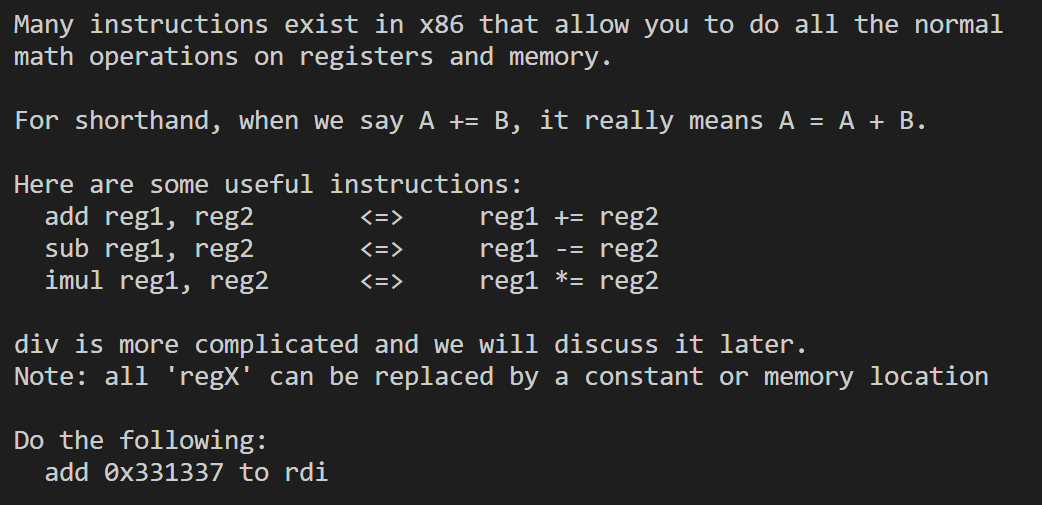
看题目要求是要把rdi寄存器的值改为0x1337,这个其实一条mov指令就可以了,但是需要考虑的是怎么被/challenge/run检测到寄存器的值是改变后的呢。
1 | vim solve.s |
1 | .intel_syntax noprefix |
1 | gcc -nostdlib -o solve.elf solve.s |
objdump -M intel -d solve.elf:此命令反汇编solve.elf文件,并以 Intel 语法输出汇编代码,以便检查汇编代码是否正确编译。objcopy --dump-section .text=solve.bin solve.elf:此命令从solve.elf中提取.text部分(包含可执行代码),并将其写入solve.bin文件。
编译脚本
1 |
|
or
1 |
|
还有一种是jdin佬给出的:
1 | import pwn |
还有一种更适合拿来调试的:
详细的使用方式见Assembly Crash Course - Connor - Live Session - 2022.09.19
1 | import pwn |
3
1 |
|
4

1 | .intel_syntax noprefix |
5

1 | .intel_syntax noprefix |
6
1 | .intel_syntax noprefix |
8
1 | .intel_syntax noprefix |
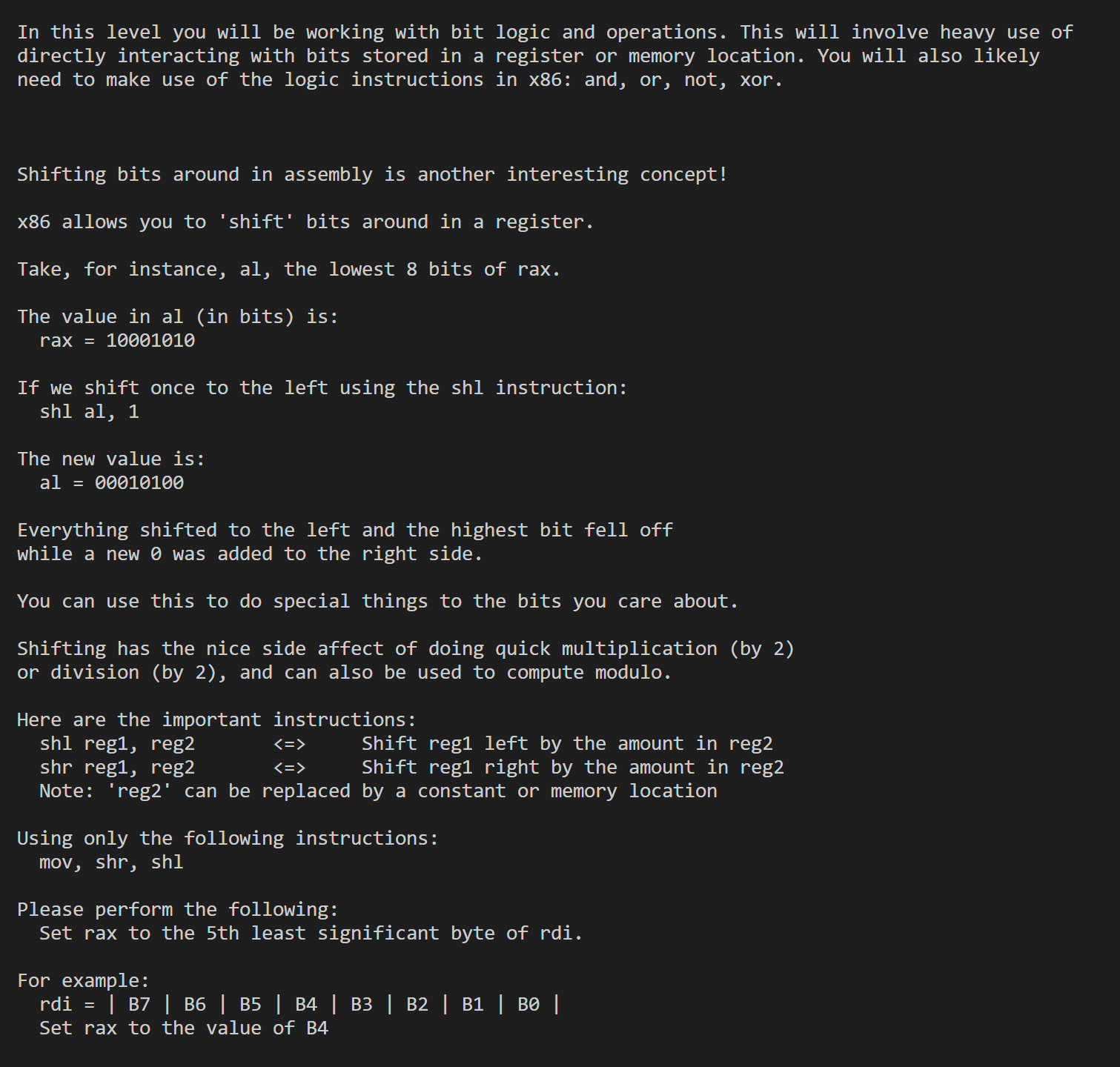
Work with bit logic and operations
9
1 | .intel_syntax noprefix |
10
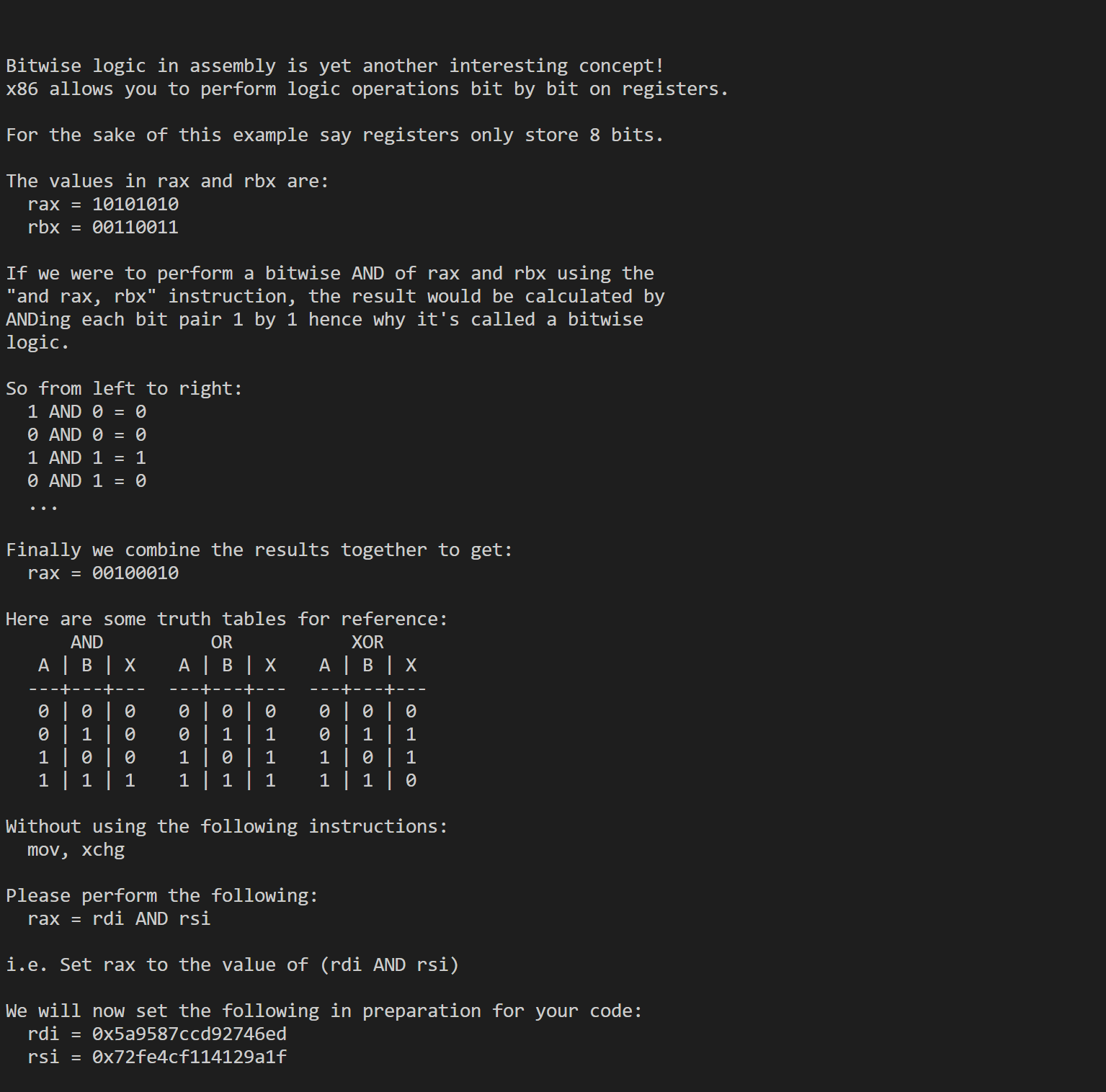
1 | .intel_syntax noprefix |
11

1 | .intel_syntax noprefix |
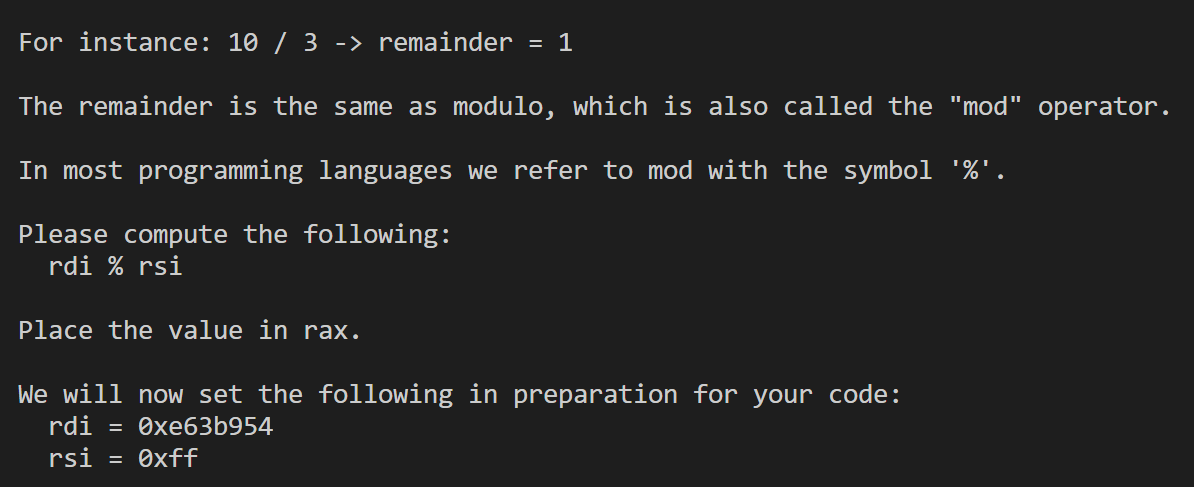
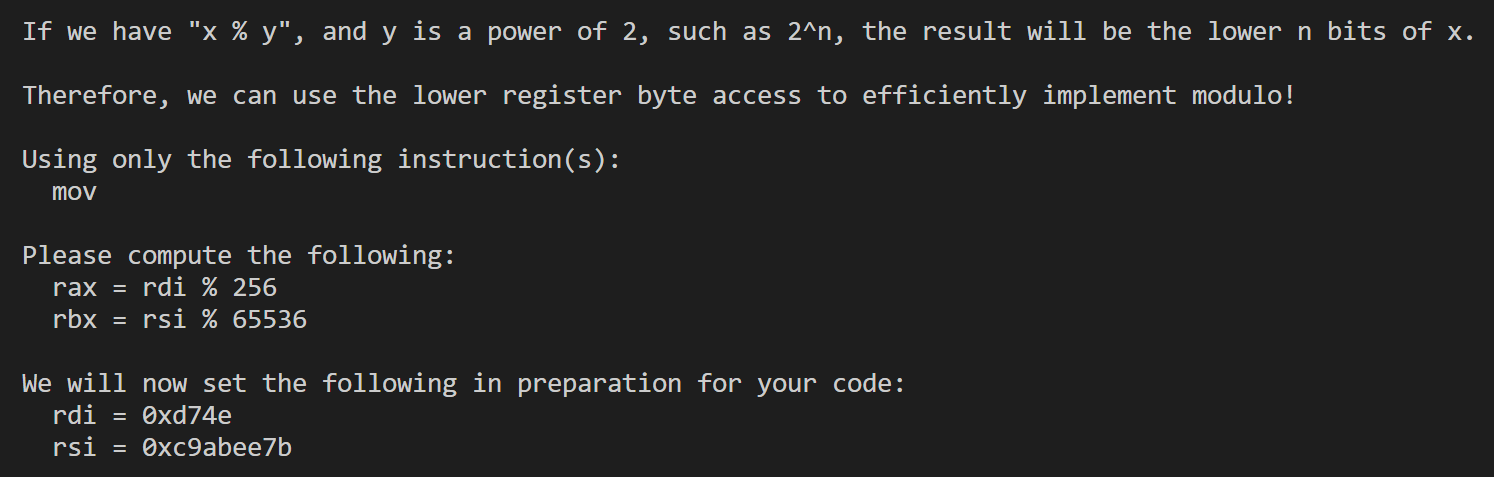
这里有一个tips就是可以使用xor rax, rax对rax寄存器清零。(对任何寄存器清零都可以这样)
Work with memory
14
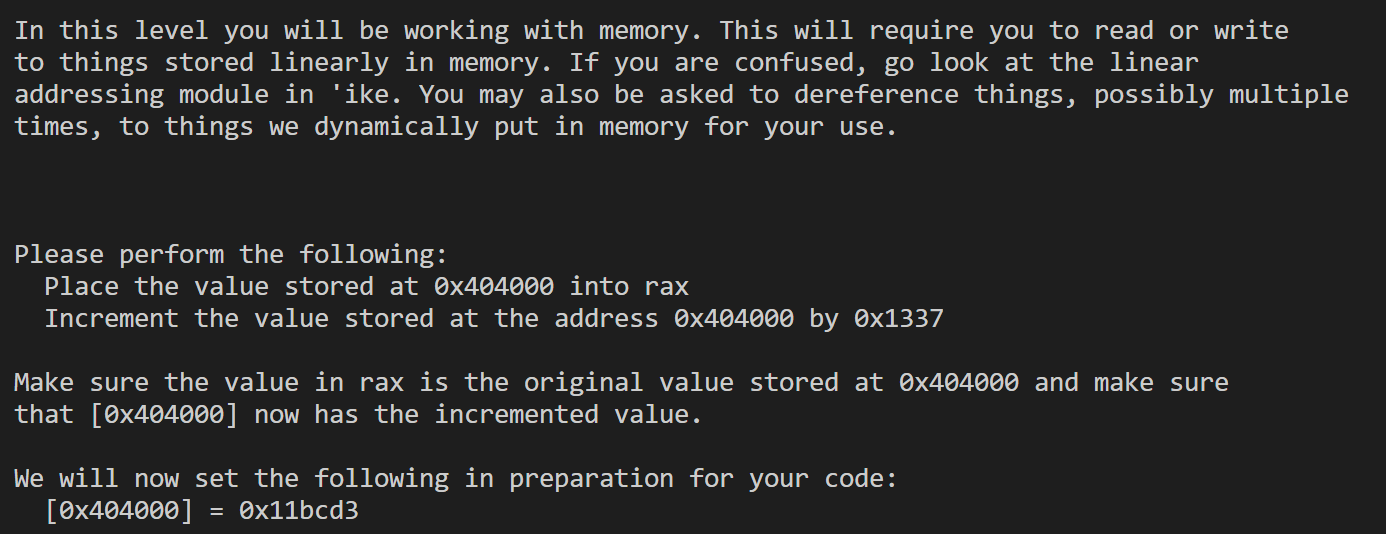
1 | .intel_syntax noprefix |
16

1 | .intel_syntax noprefix |
17
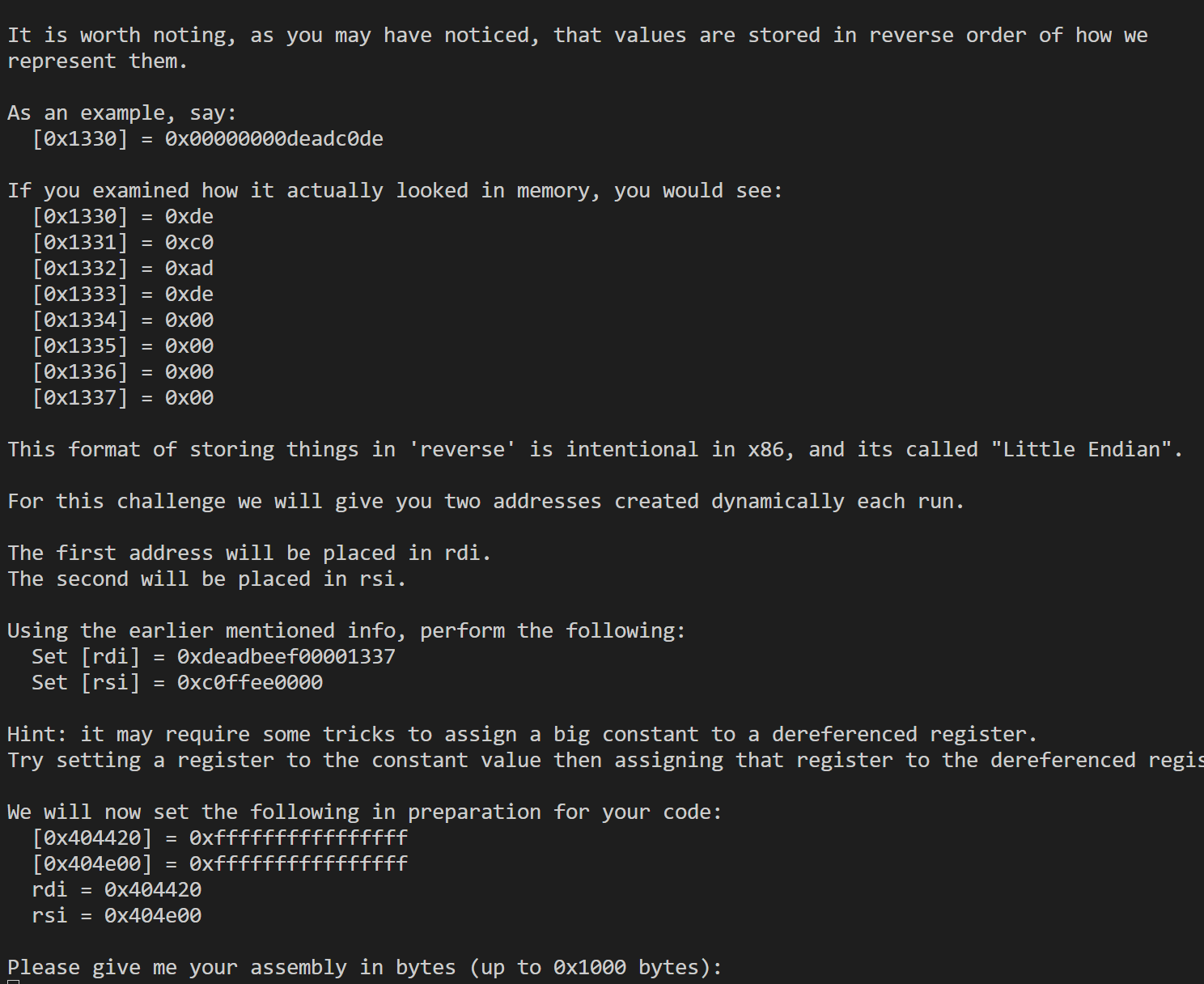
1 | .intel_syntax noprefix |
这里主要是指出了某些汇编语言中(特别是较老的指令集),可能无法直接将一个大的常数值赋给一个解引用的寄存器(即一个内存地址)。这主要是因为直接对内存操作的指令可能不支持大的立即数(即直接编码在指令中的常数值)。
为了解决这个问题,可以采取以下步骤:
设置寄存器: 首先,将大的常数值赋给一个寄存器。这通常通过
mov指令来完成,因为mov指令通常能够处理立即数到寄存器的赋值。赋值到解引用的寄存器: 然后,将包含常数值的寄存器赋给另一个寄存器,该寄存器表示一个内存地址的解引用。这样做通常涉及到对内存的写操作。
18
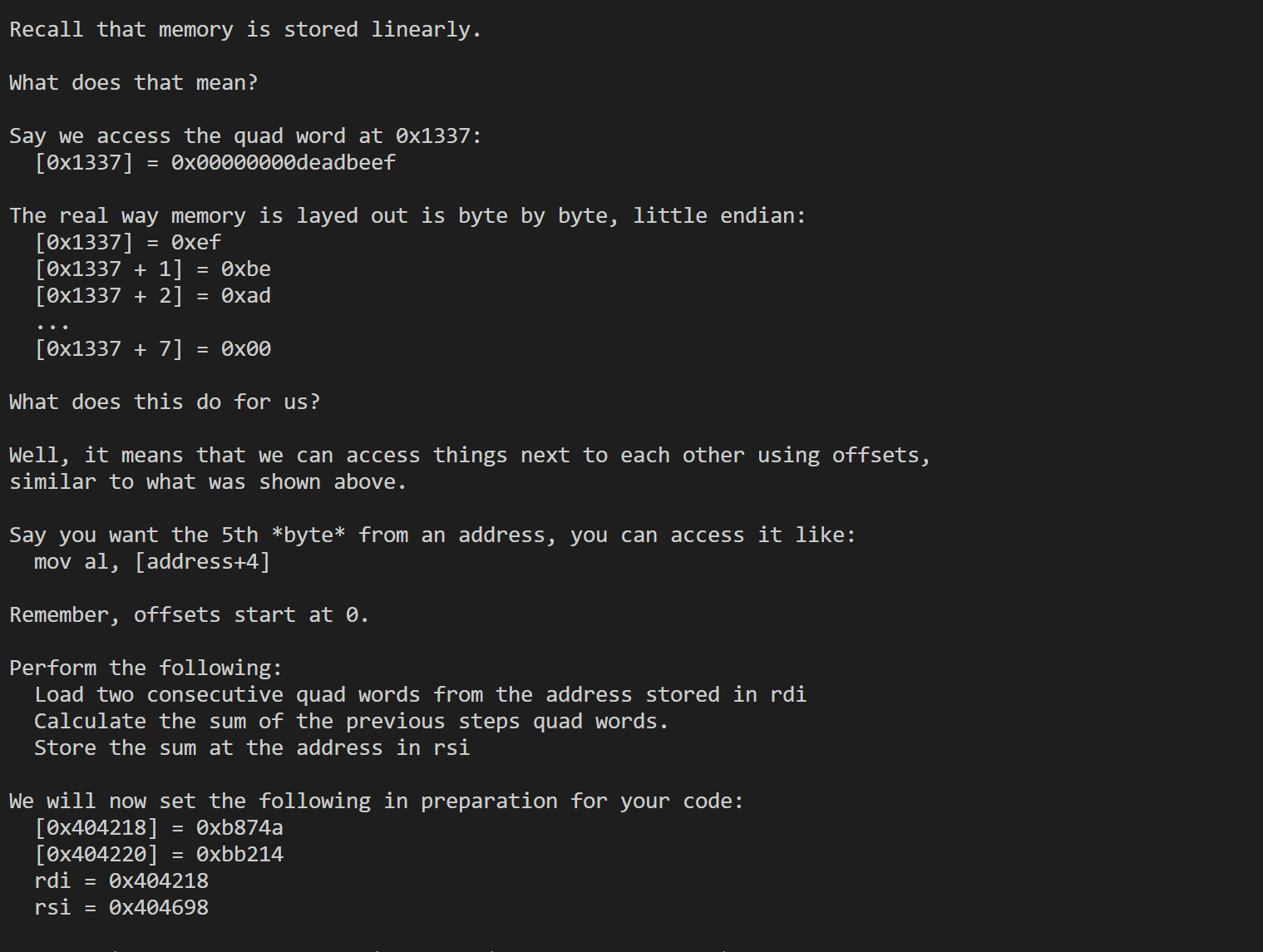
1 | .intel_syntax noprefix |
这里是指出了可以通过偏移的方式去访问值,但是要注意偏移量是从0开始的。
Work with stack
19
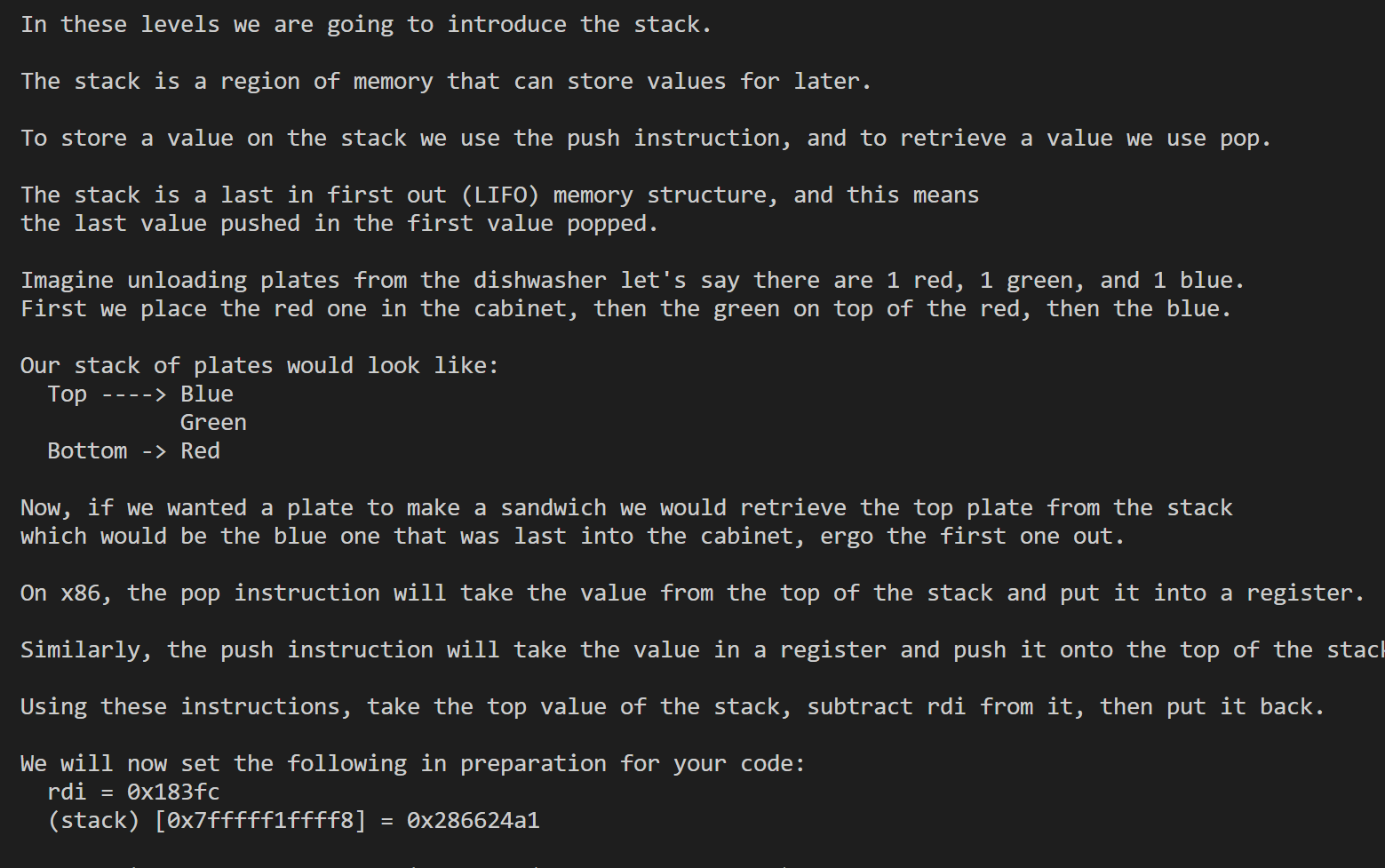
1 | .intel_syntax noprefix |
这里最开始在想pop和push是怎么知道哪块地址是栈的,然后使用mov rsp, address这种形式(这个寄存器存的值代表的栈顶指针的地址)。后面测试的时候发现不能使用mov,去掉之后反应过来本题应该是给设置好了的,不需要自己设置,直接拿值进行处理就好了,pop和push后面一般要操作的值存放的位置。
20

1 | .intel_syntax noprefix |
21
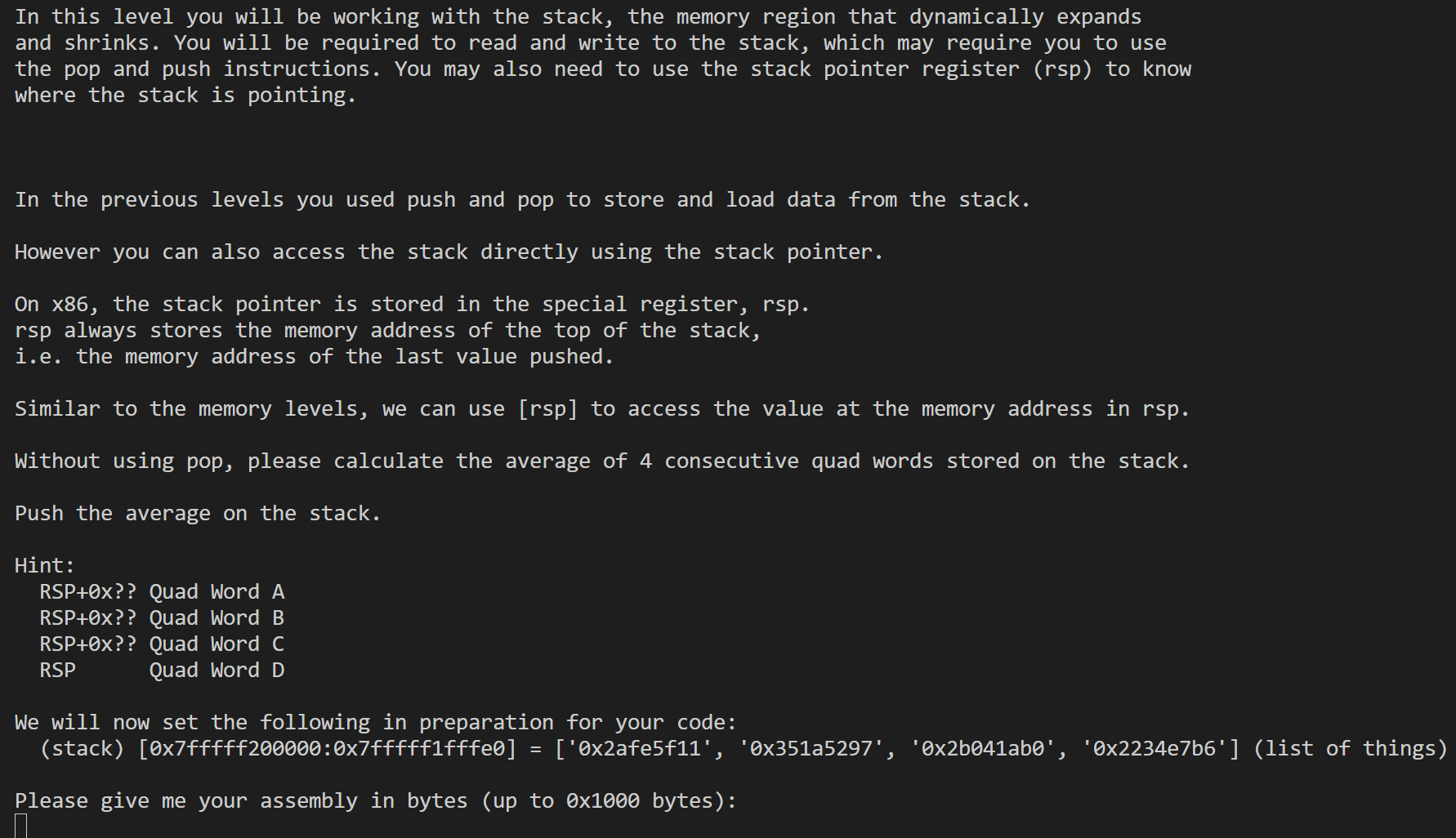
1 | .intel_syntax noprefix |
Work with control flow manipulation
24
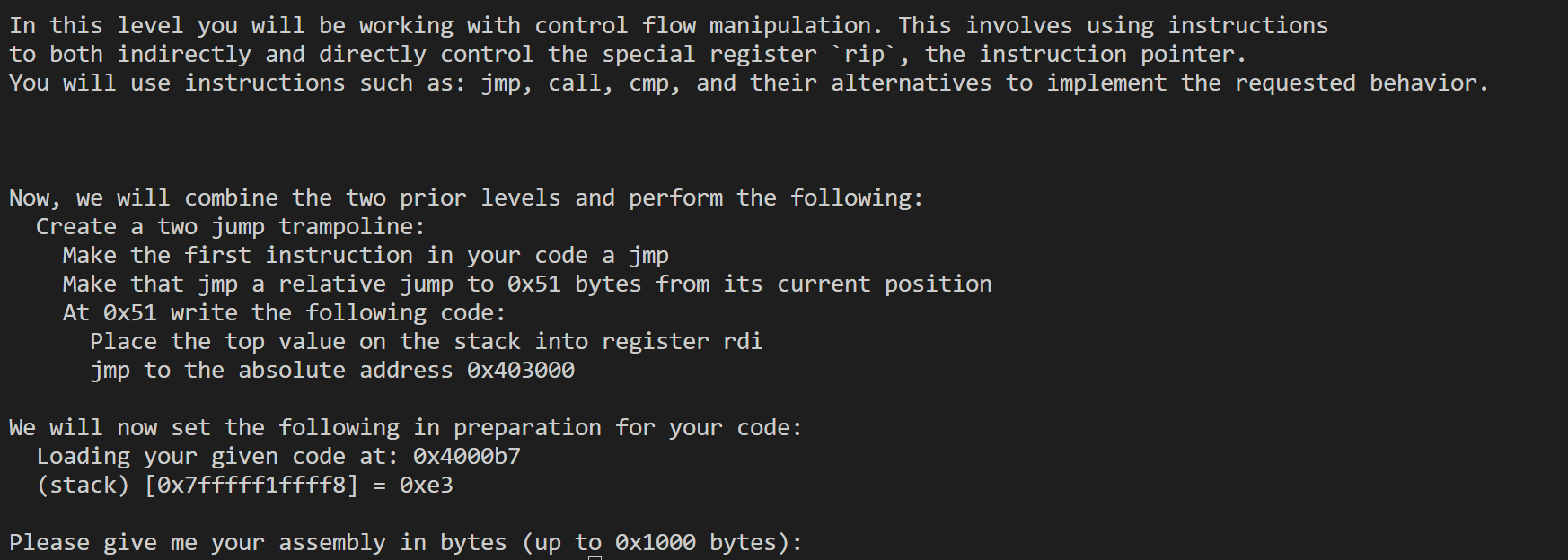
1 | .intel_syntax noprefix |
这里题目说跳到当前位置后0x51bytes,但是并没有说明包不包括jmp指令,经过测试应该是包括的,所以我们要跳到0x53。然后为了pop rdi能够在跳转之后的地址中,所以要用fill去填充,不过这里要注意因为要跳0x53,所以要填充0x51(去掉jmp指令本身的2字节)。后面要注意的是不能直接jmp 0x403000,要通过寄存器来实现。
25
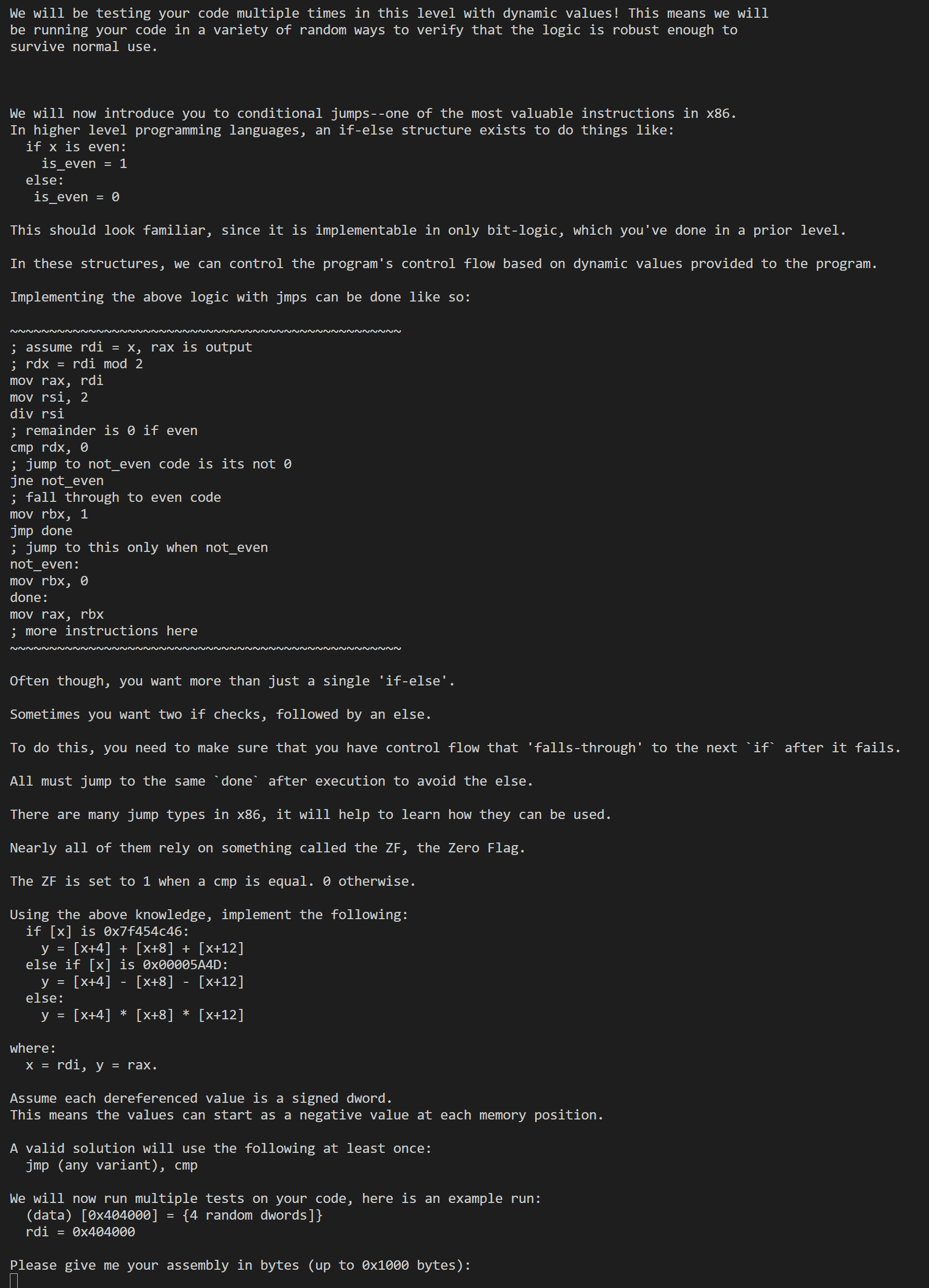
1 | .intel_syntax noprefix |
这里就是正常按照题目逻辑写就好了,但是要注意使用eax而不是rax,似乎是因为使用rax它的高位也会被补齐,导致过不了检测,使用eax则之后填进低32位,高32位会自动清零。
26
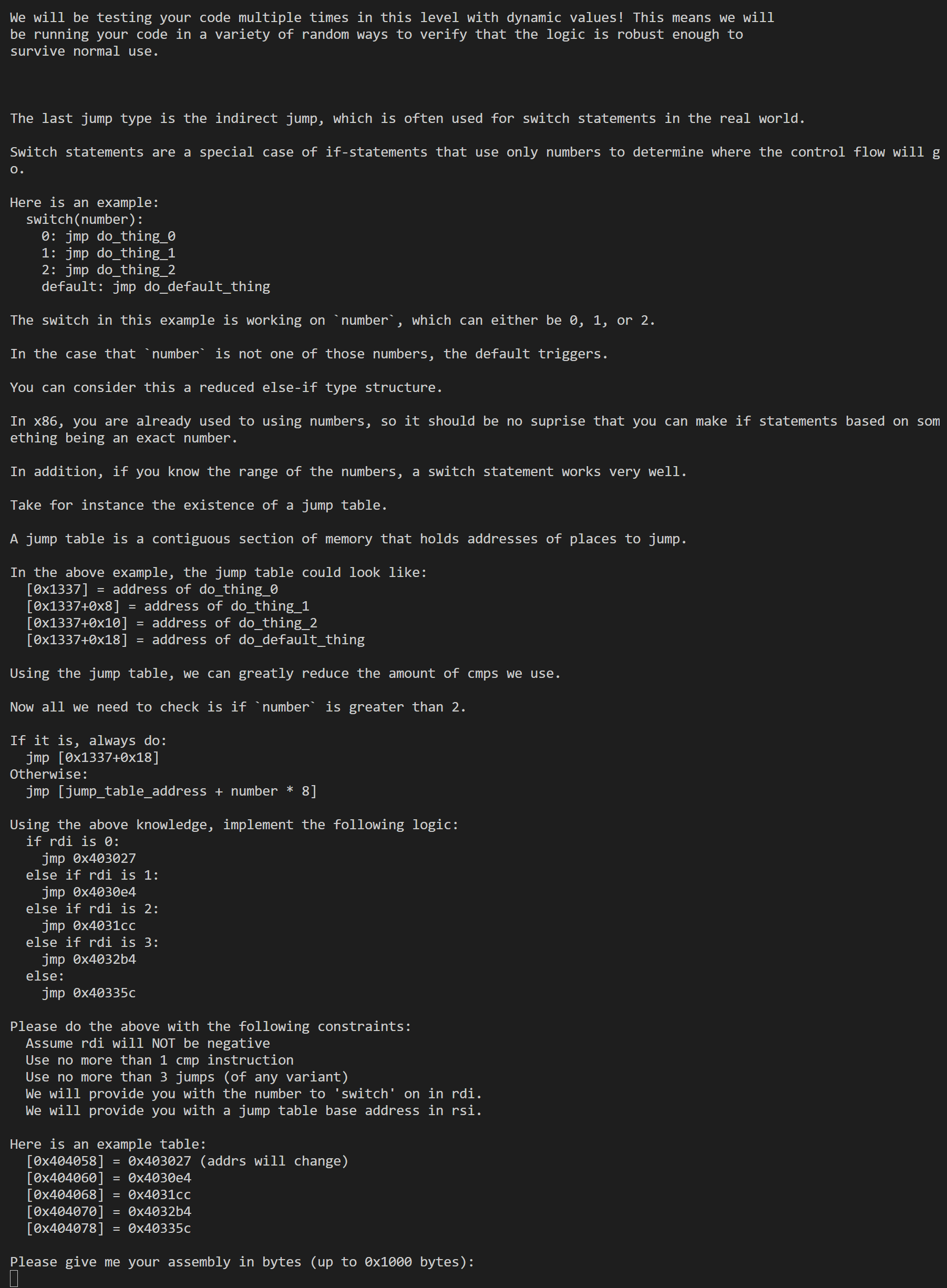
1 | .intel_syntax noprefix |
这里根据题目的示例构建jmp table表就好了,就是本题在执行的时候要等待200s之后才会给出flag,所以卡住了可能不是代码的问题。这里最后的jmp [rsi+0x20]也是根据题目中的示例表算出来的。
27
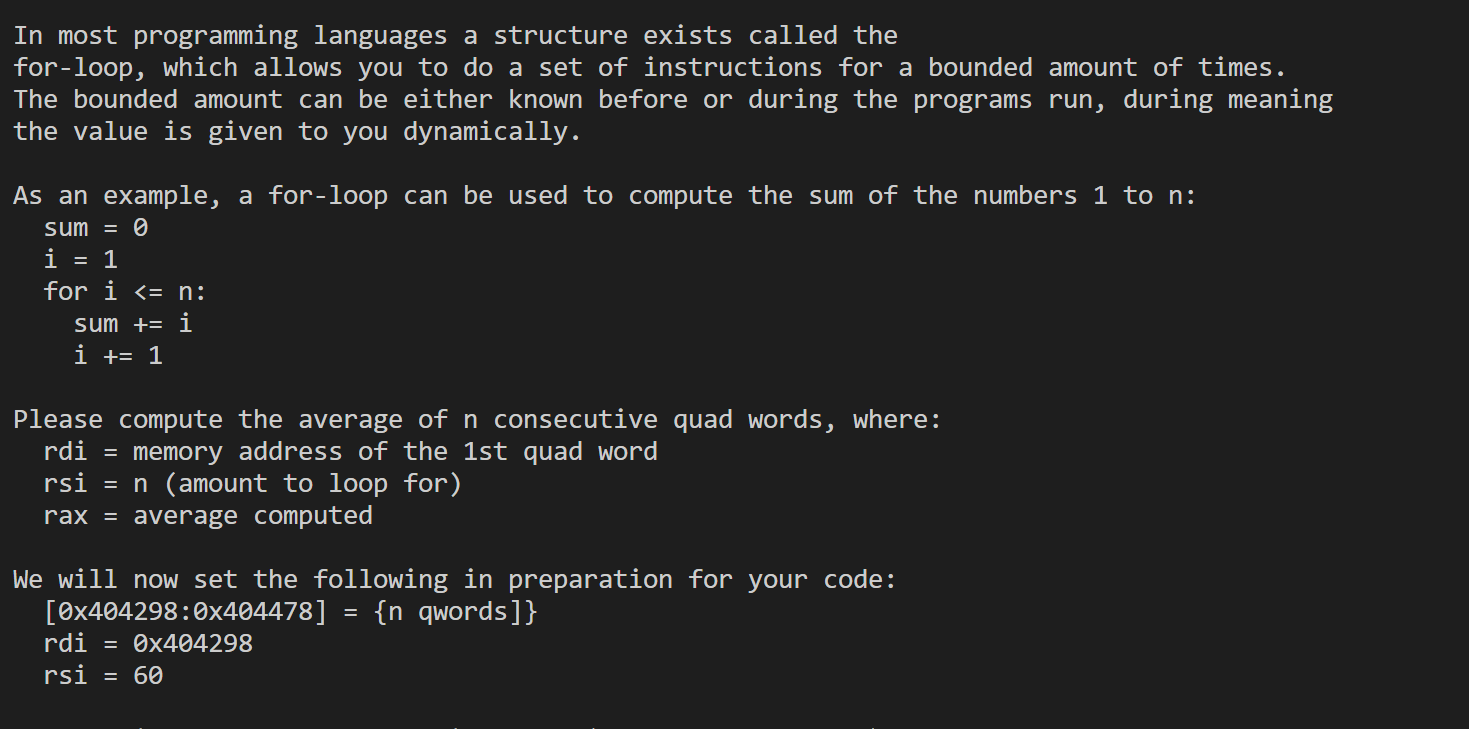
1 | .intel_syntax noprefix |
这里要先看how-to-make-a-loop-in-x86-assembly-language
然后将给的值移到对应的寄存器中然后进行计算。计算平均值的时候要注意要对rdx进行清零,这里是因为x86-64架构中div的工作方式:
128位除数:
div指令执行的是 64 位无符号整数的除法。不过,它不仅仅使用rax作为被除数。实际上,它将rdx和rax合并作为一个 128 位的整数来处理。这个 128 位整数是通过将rdx作为高 64 位,rax作为低 64 位来构成的。**需要清零
rdx**:如果rdx寄存器中有非零值,那么div指令会将这个值作为被除数的一部分。这通常会导致不正确的结果,特别是在您只希望用rax中的值作为被除数时。因此,在执行div指令之前,通常需要将rdx清零,以确保被除数只包含rax中的值。防止除法溢出:如果
rdx中包含非零值,那么合并后的 128 位整数可能会非常大,导致除法操作溢出。这种溢出会触发运行时错误。通过清零rdx,您可以避免这种情况,确保除法操作安全地进行。
28
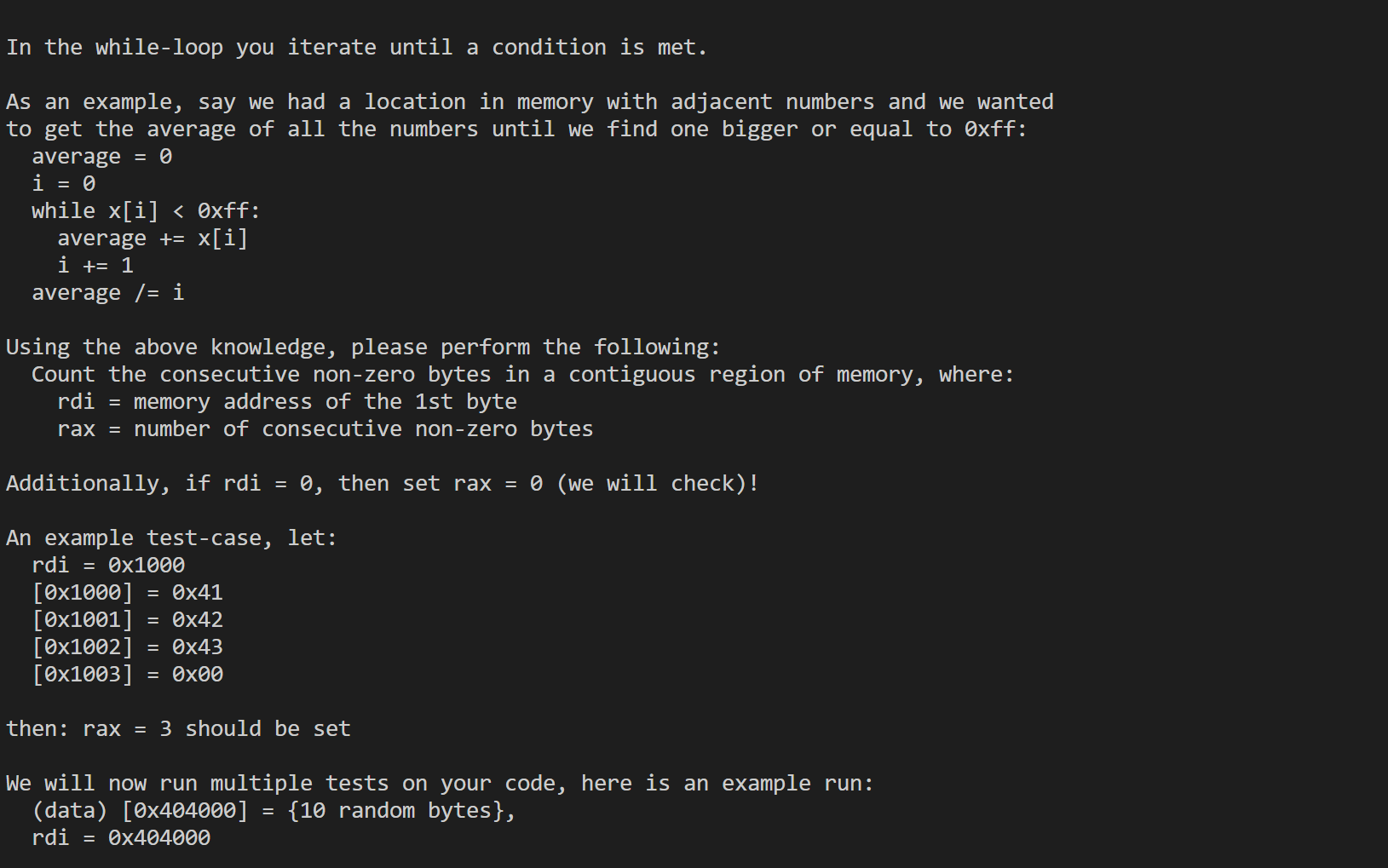
错误代码:
1 | .intel_syntax noprefix |
正确代码:
1 | .intel_syntax noprefix |
本题的相关video。
这里要明确一下题目的意思,一开始是误解了意思一直写的是题目中的那个while循环,但是不是,本题的名字为Implementing strlen。就是从给的地址开始一直数数, 如果遇到rdi中存储的地址的指向的值(dereference)为0(类似strlen函数是遇到\0),则结束循环,然后返回计数。明确了这个之后这道题就很好完成了,代码如上所示。不过要记得事先比较一下rdi是否为0(当然你可以尝试不加这个去执行然后用自己的方式去debug试试,会学到一些东西的呢!!!)
Work with functions
29
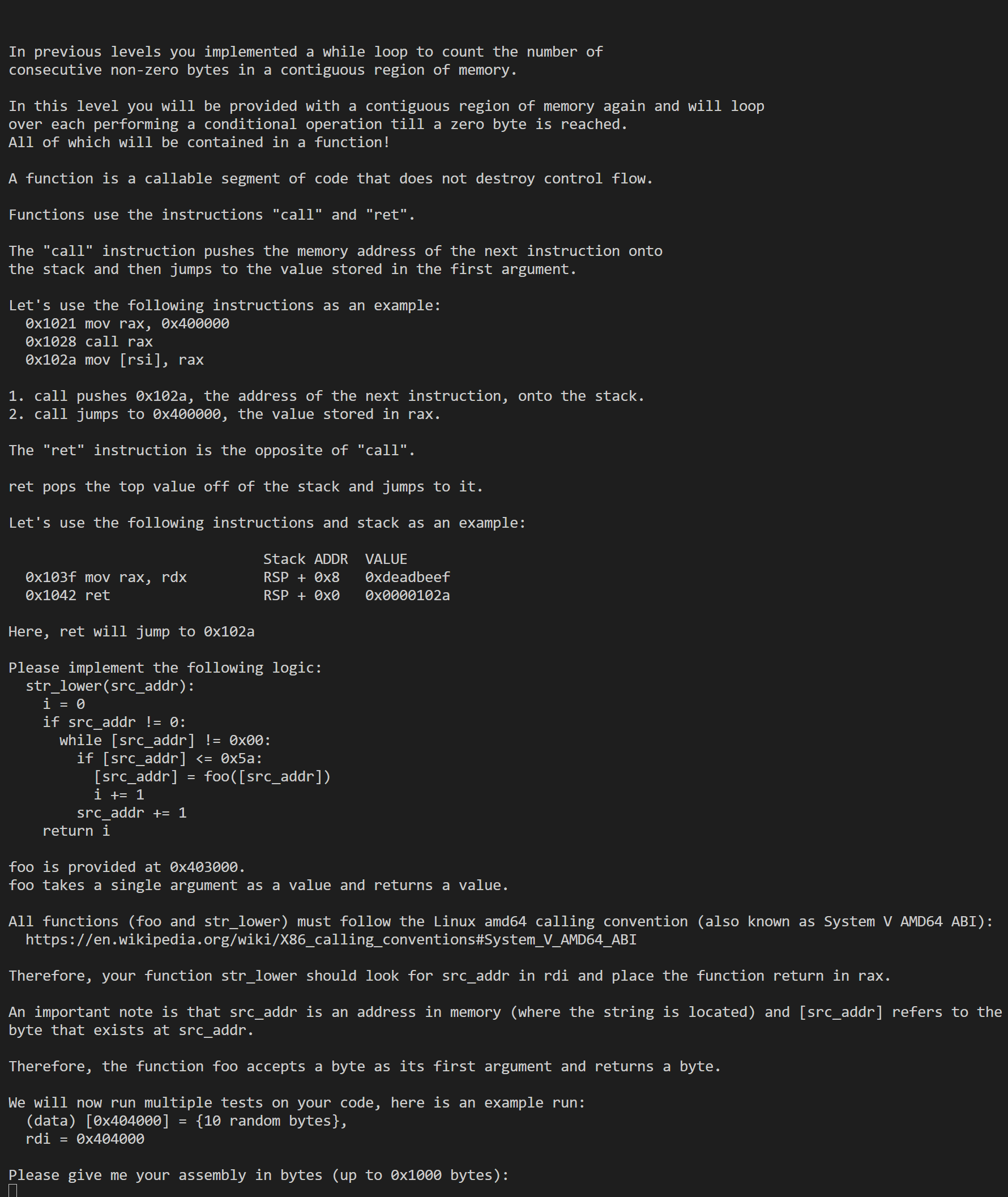
1 | .intel_syntax noprefix |
相关video
这里主要是延续了上一个题的循环,然后再加上了函数调用。关于函数调用,我们需要知道一些东西:1.函数从rdi中拿第一个参数,从rsi中拿第二个参数。2.函数的返回值存在rax中。
所以这题的难点就在于处理函数的参数,因为有的值我们是放在rdi、rax中,这里我们采用的是通过寄存器加栈的方式去先存储值,等调用函数结束后再将要放在rdi、rax中的值放回去。解决了这个这题也就解决了。
30
1 | .intel_syntax noprefix |
逻辑很简单,就是维护各种值写起来实在是太恶心了,本质逻辑就是利用桶排序来找到出现次数最多的字节。
- Title: AssembleCrash
- Author: starlitxiling
- Created at : 2023-11-10 19:20:02
- Updated at : 2025-09-10 17:08:47
- Link: http://starlitxiling.github.io/2023/11/10/AssembleCrash/
- License: This work is licensed under CC BY-NC-SA 4.0.